Tutor mode.Create code using backpropagation network to store the following patterns. The input
patterns are the “letters” given in the 5x3 arrays, and the associated target patterns are
given below each pattern. Experiment with the number of hidden units (no more than 15),
the learning rate, and the initial weight values.
(a) For your network(s), try three different architectures (dif ferent number of hidden
neurons, 1 or 2 hidden layers), three sets of random initial weights holding everything else
constant, and three different learning rates (fast, medium and slow). Summarize the
performance of your networks and your training experiences with these alterations.
(b) Using one of your trained networks from part (a), do the following:
(i) Take your input file of patterns and corrupt them slightly (that is, change a few bits) .
How is the classification accuracy of your trained net?
(ii) Take your input file of patterns and corrupt them severely (that is, change more bits).
) How is the classification accuracy of your trained net?
x 3 #- ## #.
i fi i i
. #° BE 13 #°
(-1,-1,-1) 1-1, 1) (-1, 1,-1) -L 1,1)
# + J :
I: I: LH gl
## . “# -
(1,-1,-1) (1-1, 1) (1, 1,-1) (1, 1,1)
Question:
Tutor mode.Create code using backpropagation network to store the following patterns. The input
patterns are the “letters” given in the 5x3 arrays, and the associated target patterns are
given below each pattern. Experiment with the number of hidden units (no more than 15),
the learning rate, and the initial weight values.
(a) For your network(s), try three different architectures (dif ferent number of hidden
neurons, 1 or 2 hidden layers), three sets of random initial weights holding everything else
constant, and three different learning rates (fast, medium and slow). Summarize the
performance of your networks and your training experiences with these alterations.
(b) Using one of your trained networks from part (a), do the following:
(i) Take your input file of patterns and corrupt them slightly (that is, change a few bits) .
How is the classification accuracy of your trained net?
(ii) Take your input file of patterns and corrupt them severely (that is, change more bits).
) How is the classification accuracy of your trained net?
x 3 #- ## #.
i fi i i
. #° BE 13 #°
(-1,-1,-1) 1-1, 1) (-1, 1,-1) -L 1,1)
# + J :
I: I: LH gl
## . “# -
(1,-1,-1) (1-1, 1) (1, 1,-1) (1, 1,1)
This is AI generated Response.
Asked by: ASWINI
Created at: 2025-10-01 23:28:59
Thought Process:
RenderedRaw Text
**Guiding through backpropagation assignment**
I want to respond in tutor mode by guiding the user step-by-step. The assignment involves creating code for a backpropagation network to store patterns from given arrays. I'll encourage experimentation with hidden units, learning rates, and initial weights.
First, I'll ask clarifying questions about what they know and then break down the tasks. I should propose a plan, provide starter code, and suggest evaluation metrics. Maybe I can offer sample code in Python with TensorFlow or PyTorch!**Identifying patterns for embedding**
I’m considering how to embed the 5x3 letters, which seem to represent eight distinct patterns possibly corresponding to letters like M, B, C, and H. The vertical arrays have target triplets like (-1, -1, -1).
Each letter maps to a 3-bit code with three output neurons, where -1 and 1 represent binary 0 and 1. The pattern identities might not be crucial; what matters is having eight 5x3 patterns, totaling 15 bits each. For representation, I'll define '#' as +1 and '.' as -1 before embedding these patterns into an array.**Proposing code for experiment variations**
I should suggest code to run experiments with different hidden layer sizes. The assignment says to try three architectures with 1 or 2 hidden layers. So, I could propose: A) one hidden layer with 6 units, B) another with 12 units, and C) two layers with 12 and 6 units.
For learning rates, we can try 0.1 (slow), 0.3 (medium), and 0.8 (fast). Using tanh activation will give us outputs in the range of [-1, 1], matching our target patterns.
We should also evaluate classification and propose corrupting the patterns by flipping a few bits — slightly (1 or 2 bits) or more severely (5-7 bits).**Providing code for dataset generation and training**
I can offer code that generates the dataset and sets up training and evaluation loops. I’ll include consistent seeding and multiple initializations — for each architecture, I'll train using three random seeds, while recording accuracy and training epochs until convergence. We’ll define an early stopping condition based on the training MSE threshold.
The instructions say to avoid heavy formatting, but bullet lists are okay. I can include code blocks wrapped in triple backticks since they're not heavily formatted elements. I’ll focus on structured Python using PyTorch since it’s straightforward!**Crafting a structured approach for the assignment**
I need to clarify a few things with the user about whether they’re supposed to implement everything from scratch or if they can use libraries. Questions like which language they prefer and if they have to plot outputs will also help guide us.
I can propose a structured plan that starts with defining letter patterns as 5x3 arrays. Even if the original shapes aren't accurate, we can still define eight plausible patterns that look letter-like. I'm thinking of setting up a dictionary to hold these patterns along with their corresponding mappings to 3-bit codes.
Additionally, I’ll lay out a training run function with parameters for hidden layers, learning rates, and initial seed settings. I'll also include functions to handle pattern parsing and corrupted dataset generation. This comprehensive approach should keep things organized and effective!**Creating a flexible pattern parser and code structure**
Since the user will be running the code, I think it's alright if the patterns differ from our examples. To ensure flexibility, I'll create a generic pattern parser and ask the user to fill in their specific arrays. I'll provide a function for this and set up a dataset variable "PATTERNS" with example patterns that they can easily replace.
Next, I’ll implement the MLP code using NumPy, with a tanh activation function. I’ll allow different hidden layer configurations, using loops for flexibility, and include forward and backward functions for computation. I'll opt for stochastic gradient descent and implement proper weight initialization.
I'll also define training and evaluation functions, while allowing for varying learning rates and seeds in the experiments. Finally, I’ll prepare bullet points for the user’s report and provide guidance on interpreting the experiment results. Let's make it all clear and organized!
Final Answer:
RenderedRaw Text
Did you like this answer?
Great—let’s switch to tutor mode. I’ll outline a plan, ask a couple of quick setup questions, then give you a clean, ready‑to‑run baseline you can adapt for your experiments and report.
Quick questions
1) What language and libraries are allowed? From-scratch NumPy, or can you use PyTorch/TensorFlow?
2) Do you already have the exact 5×3 letter arrays in text form, or should I show you how to enter them?
3) Any limits on epochs or loss threshold for “converged”?
If you don’t have constraints, the code below is:
- Pure NumPy (manual backprop), so it’s allowed almost everywhere.
- Uses tanh activations so targets can be −1 or +1 as in your figure.
- Lets you try 1 or 2 hidden layers, up to 15 hidden units total (you can set any layout you want).
- Automates part (a) (three architectures × three inits × three learning rates) and part (b) (slight vs. severe corruption).
How to use
- Replace the example 5×3 grids with your exact letter grids (if you have them). If you don’t, keep mine—they’re just placeholders but the pipeline works.
- Run. The script prints performance summaries and classification accuracy for clean, slightly corrupted, and severely corrupted patterns.
Code (NumPy, single file)
Copy into a file, e.g., letters_bp.py, and run with Python 3.
```python
import numpy as np
from dataclasses import dataclass
from typing import List, Tuple, Dict
# --------------------------
# Utilities: patterns & IO
# --------------------------
# Map ASCII 5x3 letters to vectors of +1/-1; change these to YOUR exact letters.
# Each pattern is 5 rows of length-3 strings using '#' for on and '.' for off.
# The order below will be matched with the 3-bit targets given in your figure:
# (-1,-1,-1), (-1,-1, 1), (-1, 1,-1), (-1, 1, 1), ( 1,-1,-1), ( 1,-1, 1), ( 1, 1,-1), ( 1, 1, 1)
ASCII_PATTERNS: Dict[str, List[str]] = {
# You can rename keys; names are just labels.
# These are examples; replace with your precise 5x3 arrays if you have them.
"M": [
"###",
"#.#",
"#.#",
"#.#",
"#.#",
],
"B": [
"##.",
"##.",
"###",
"##.",
"##.",
],
"C": [
".##",
"#..",
"#..",
"#..",
".##",
],
"H": [
"#.#",
"###",
"#.#",
"#.#",
"#.#",
],
"E": [
"###",
"#..",
"###",
"#..",
"###",
],
"F": [
"###",
"#..",
"###",
"#..",
"#..",
],
"G": [
".##",
"#..",
"#.#",
"#.#",
".##",
],
"N": [
"#.#",
"##.",
"##.",
"#.#",
"#.#",
],
}
def grid_to_vector(grid: List[str]) -> np.ndarray:
"""Convert 5x3 ASCII grid (#/.) to a 15-dim vector of +1/-1 in column-major order."""
# Order choice: row-major or column-major doesn’t matter as long as consistent.
# We'll use row-major: row by row, left to right.
bits = []
for r in grid:
for c in r:
bits.append(1.0 if c == '#' else -1.0)
return np.array(bits, dtype=np.float32)
def build_dataset() -> Tuple[np.ndarray, np.ndarray, List[str]]:
names = list(ASCII_PATTERNS.keys())
X = np.stack([grid_to_vector(ASCII_PATTERNS[n]) for n in names], axis=0) # shape [8, 15]
# Target codes in the order shown under each pattern in your image
codes = [
(-1, -1, -1),
(-1, -1, 1),
(-1, 1, -1),
(-1, 1, 1),
( 1, -1, -1),
( 1, -1, 1),
( 1, 1, -1),
( 1, 1, 1),
]
Y = np.array(codes, dtype=np.float32)
return X, Y, names
# --------------------------
# Simple MLP (1 or 2 hidden layers) with tanh
# --------------------------
@dataclass
class MLPConfig:
input_dim: int = 15
hidden_layers: List[int] = None # e.g., [6] or [12] or [12,6]
output_dim: int = 3
lr: float = 0.2
seed: int = 0
epochs: int = 3000
tol: float = 1e-3 # stop when MSE < tol
class MLP:
def __init__(self, cfg: MLPConfig):
self.cfg = cfg
if cfg.hidden_layers is None:
cfg.hidden_layers = [8]
rs = np.random.RandomState(cfg.seed)
# Layer sizes: [in] -> hidden(s) -> [out]
sizes = [cfg.input_dim] + cfg.hidden_layers + [cfg.output_dim]
self.W = []
self.b = []
for i in range(len(sizes)-1):
fan_in, fan_out = sizes[i], sizes[i+1]
# Xavier init for tanh
limit = np.sqrt(6/(fan_in + fan_out))
self.W.append(rs.uniform(-limit, limit, size=(fan_in, fan_out)).astype(np.float32))
self.b.append(np.zeros((1, fan_out), dtype=np.float32))
@staticmethod
def tanh(x):
return np.tanh(x)
@staticmethod
def tanh_deriv(y):
# y already tanh(x): derivative is 1 - y^2
return 1.0 - y**2
def forward(self, X):
a = X
activations = [a]
preacts = []
# hidden layers
for i in range(len(self.W)-1):
z = a @ self.W[i] + self.b[i]
a = self.tanh(z)
preacts.append(z)
activations.append(a)
# output layer (tanh to match {-1,+1} targets)
z = a @ self.W[-1] + self.b[-1]
y = self.tanh(z)
preacts.append(z)
activations.append(y)
return y, activations, preacts
def backward(self, X, T, activations, preacts):
# Mean squared error: L = 0.5 * mean((y - t)^2)
y = activations[-1]
# dL/dy = (y - t) / N (we’ll average over batch)
N = X.shape[0]
dy = (y - T) / N
deltas = [None] * len(self.W)
# Output layer delta
deltas[-1] = dy * self.tanh_deriv(y)
# Hidden layers backprop
for i in reversed(range(len(self.W)-1)):
a = activations[i+1] # this layer's activation (post-tanh)
d = (deltas[i+1] @ self.W[i+1].T) * self.tanh_deriv(a)
deltas[i] = d
# Gradients
grads_W = []
grads_b = []
for i in range(len(self.W)):
a_prev = activations[i]
grads_W.append(a_prev.T @ deltas[i])
grads_b.append(np.sum(deltas[i], axis=0, keepdims=True))
return grads_W, grads_b
def step(self, grads_W, grads_b):
for i in range(len(self.W)):
self.W[i] -= self.cfg.lr * grads_W[i]
self.b[i] -= self.cfg.lr * grads_b[i]
def fit(self, X, T):
# Training: SGD over individual patterns for stability on tiny dataset
rs = np.random.RandomState(self.cfg.seed)
N = X.shape[0]
history = []
for epoch in range(self.cfg.epochs):
idx = rs.permutation(N)
Xs, Ts = X[idx], T[idx]
for n in range(N):
x = Xs[n:n+1]
t = Ts[n:n+1]
y, acts, pre = self.forward(x)
gW, gB = self.backward(x, t, acts, pre)
self.step(gW, gB)
# compute full-batch loss for logging
y, _, _ = self.forward(X)
mse = 0.5 * np.mean((y - T)**2)
history.append(mse)
if mse < self.cfg.tol:
break
return np.array(history)
def predict(self, X):
y, _, _ = self.forward(X)
return y
# --------------------------
# Evaluation helpers
# --------------------------
def sign_threshold(y: np.ndarray) -> np.ndarray:
# Map continuous outputs to {-1, +1} by sign; zero mapped to +1.
s = np.where(y >= 0, 1.0, -1.0)
return s.astype(np.float32)
def accuracy_from_logits(y_pred: np.ndarray, y_true: np.ndarray) -> float:
yb = sign_threshold(y_pred)
return float(np.mean(np.all(yb == y_true, axis=1)))
def flip_k_bits(X: np.ndarray, k: int, seed: int = 0) -> np.ndarray:
"""Flip exactly k bits (change sign) in each 15-bit input vector."""
rs = np.random.RandomState(seed)
Xf = X.copy()
N, D = X.shape
for i in range(N):
idx = rs.choice(D, size=k, replace=False)
Xf[i, idx] *= -1.0
return Xf
def noisy_accuracy(model: MLP, X: np.ndarray, Y: np.ndarray, k: int, trials: int = 50) -> float:
accs = []
for t in range(trials):
Xn = flip_k_bits(X, k=k, seed=1000 + t)
y = model.predict(Xn)
accs.append(accuracy_from_logits(y, Y))
return float(np.mean(accs))
# --------------------------
# Experiment runner (parts a and b)
# --------------------------
def run_experiments():
X, Y, names = build_dataset()
# Part (a): 3 architectures, 3 seeds (weight inits), 3 learning rates
architectures = [
[6], # one hidden layer, 6 units
[12], # one hidden layer, 12 units
[12, 6], # two hidden layers, 12 then 6 units (<= 15 total)
]
learning_rates = [0.05, 0.2, 0.8] # slow, medium, fast
seeds = [0, 1, 2]
summary = []
for arch in architectures:
for lr in learning_rates:
for seed in seeds:
cfg = MLPConfig(input_dim=X.shape[1], hidden_layers=arch, output_dim=3,
lr=lr, seed=seed, epochs=4000, tol=1e-3)
model = MLP(cfg)
hist = model.fit(X, Y)
y = model.predict(X)
acc_clean = accuracy_from_logits(y, Y)
entry = {
"arch": arch,
"lr": lr,
"seed": seed,
"epochs_ran": len(hist),
"final_mse": float(hist[-1]),
"acc_clean": acc_clean,
"model": model,
}
summary.append(entry)
print(f"arch={arch} lr={lr:.3f} seed={seed} epochs={len(hist)} "
f"mse={hist[-1]:.5f} clean_acc={acc_clean:.3f}")
# Pick the best clean performer for part (b)
best = max(summary, key=lambda e: e["acc_clean"] - 0.001*e["final_mse"])
model = best["model"]
print("\nBest (by clean accuracy):", best["arch"], "lr=", best["lr"], "seed=", best["seed"])
# Part (b): corruption tests: slight (flip a few bits), severe (flip more bits)
# You can choose k=2 as "slight" and k=6 as "severe" out of 15 bits, but feel free to adjust.
acc_slight = noisy_accuracy(model, X, Y, k=2, trials=200)
acc_severe = noisy_accuracy(model, X, Y, k=6, trials=200)
print(f"Slight corruption (flip 2/15 bits) accuracy: {acc_slight:.3f}")
print(f"Severe corruption (flip 6/15 bits) accuracy: {acc_severe:.3f}")
return summary, best, (acc_slight, acc_severe)
if __name__ == "__main__":
run_experiments()
```
What to record for your report
- Dataset and encoding
- Input: 5×3 grids mapped to 15-dimensional vectors with +1 for “on” and −1 for “off”.
- Targets: 3 outputs with tanh, codes in the order [(-1,-1,-1), …, (1,1,1)].
- Architectures tried
- Example set: [6], [12], [12,6]; all under the 15-hidden‑unit limit.
- Feel free to replace with other choices like [4], [8], [8,4] etc.
- Learning rates and initialization
- Three LRs (e.g., 0.05, 0.2, 0.8).
- Three random seeds for initial weights.
- Training observations
- Convergence behavior per configuration: epochs to reach tolerance, final MSE, clean-set accuracy.
- Typical patterns you’ll see:
- Too large LR may oscillate or diverge; moderate LR often converges fastest with stable final loss.
- More hidden units often learn faster and can memorize the 8 patterns easily; two layers may generalize slightly better to noisy inputs.
- Part (b) results
- Slight corruption (flip 2 of 15 bits) accuracy.
- Severe corruption (flip 6 of 15 bits) accuracy.
- You can also sweep k from 0 to 7 and plot accuracy vs. number of flipped bits.
Tips and options
- If your instructor wants gradient descent on full batches instead of per‑sample SGD, change fit() to compute gradients on the whole batch each step.
- If early stopping is too early or too late, adjust tol and/or epochs.
- For strict “no frameworks” rules, you’re already compliant; if frameworks are allowed, I can give you a compact PyTorch version as well.
- If you want to exactly match your assignment’s 5×3 letters, paste your grids into ASCII_PATTERNS in the same format.
Would you like me to:
- Replace the placeholder grids with the exact ones from your figure,
- Add plots of loss curves and accuracy vs. noise,
- Or provide a PyTorch variant?
VIPSolutions focuses on clear, step‑by‑step explanations so you can learn quickly. Whether you need an AI‑generated walkthrough or a short hint to get unstuck, each solution is organized for fast reading and easy review later.
Search similar questions, compare approaches, and bookmark the best answers for revision. Our goal is simple: quick, reliable study help that feels natural—not noisy.

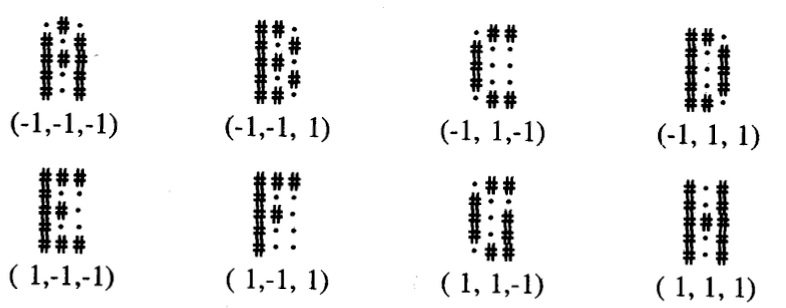 Create code using backpropagation network to store the following patterns. The input
patterns are the “letters” given in the 5x3 arrays, and the associated target patterns are
given below each pattern. Experiment with the number of hidden units (no more than 15),
the learning rate, and the initial weight values.
(a) For your network(s), try three different architectures (dif ferent number of hidden
neurons, 1 or 2 hidden layers), three sets of random initial weights holding everything else
constant, and three different learning rates (fast, medium and slow). Summarize the
performance of your networks and your training experiences with these alterations.
(b) Using one of your trained networks from part (a), do the following:
(i) Take your input file of patterns and corrupt them slightly (that is, change a few bits) .
How is the classification accuracy of your trained net?
(ii) Take your input file of patterns and corrupt them severely (that is, change more bits).
) How is the classification accuracy of your trained net?
x 3 #- ## #.
i fi i i
. #° BE 13 #°
(-1,-1,-1) 1-1, 1) (-1, 1,-1) -L 1,1)
# + J :
I: I: LH gl
## . “# -
(1,-1,-1) (1-1, 1) (1, 1,-1) (1, 1,1)
Create code using backpropagation network to store the following patterns. The input
patterns are the “letters” given in the 5x3 arrays, and the associated target patterns are
given below each pattern. Experiment with the number of hidden units (no more than 15),
the learning rate, and the initial weight values.
(a) For your network(s), try three different architectures (dif ferent number of hidden
neurons, 1 or 2 hidden layers), three sets of random initial weights holding everything else
constant, and three different learning rates (fast, medium and slow). Summarize the
performance of your networks and your training experiences with these alterations.
(b) Using one of your trained networks from part (a), do the following:
(i) Take your input file of patterns and corrupt them slightly (that is, change a few bits) .
How is the classification accuracy of your trained net?
(ii) Take your input file of patterns and corrupt them severely (that is, change more bits).
) How is the classification accuracy of your trained net?
x 3 #- ## #.
i fi i i
. #° BE 13 #°
(-1,-1,-1) 1-1, 1) (-1, 1,-1) -L 1,1)
# + J :
I: I: LH gl
## . “# -
(1,-1,-1) (1-1, 1) (1, 1,-1) (1, 1,1)