Tutor ModeCreate code using backpropagation network to store the following patterns. The input
patterns are the “letters” given in the 5x3 arrays, and the associated target patterns are
given below each pattern. Experiment with the number of hidden units (no more than 15),
the learning rate, and the initial weight values.
(a) For your network(s), try three different architectures (dif ferent number of hidden
neurons, 1 or 2 hidden layers), three sets of random initial weights holding everything else
constant, and three different learning rates (fast, medium and slow). Summarize the
performance of your networks and your training experiences with these alterations.
(b) Using one of your trained networks from part (a), do the following:
(i) Take your input file of patterns and corrupt them slightly (that is, change a few bits) .
How is the classification accuracy of your trained net?
(ii) Take your input file of patterns and corrupt them severely (that is, change more bits).
) How is the classification accuracy of your trained net?
x 3 #- ## #.
i fi i i
. #° BE 13 #°
(-1,-1,-1) 1-1, 1) (-1, 1,-1) -L 1,1)
# + J :
I: I: LH gl
## . “# -
(1,-1,-1) (1-1, 1) (1, 1,-1) (1, 1,1)
Question:
Tutor ModeCreate code using backpropagation network to store the following patterns. The input
patterns are the “letters” given in the 5x3 arrays, and the associated target patterns are
given below each pattern. Experiment with the number of hidden units (no more than 15),
the learning rate, and the initial weight values.
(a) For your network(s), try three different architectures (dif ferent number of hidden
neurons, 1 or 2 hidden layers), three sets of random initial weights holding everything else
constant, and three different learning rates (fast, medium and slow). Summarize the
performance of your networks and your training experiences with these alterations.
(b) Using one of your trained networks from part (a), do the following:
(i) Take your input file of patterns and corrupt them slightly (that is, change a few bits) .
How is the classification accuracy of your trained net?
(ii) Take your input file of patterns and corrupt them severely (that is, change more bits).
) How is the classification accuracy of your trained net?
x 3 #- ## #.
i fi i i
. #° BE 13 #°
(-1,-1,-1) 1-1, 1) (-1, 1,-1) -L 1,1)
# + J :
I: I: LH gl
## . “# -
(1,-1,-1) (1-1, 1) (1, 1,-1) (1, 1,1)
This is AI generated Response.
Asked by: ASWINI
Created at: 2025-10-01 23:50:10
Thought Process:
RenderedRaw Text
**Mapping target patterns**
I'm analyzing a figure that likely shows eight patterns corresponding to letters like M, B, C, and H. The target outputs are 3-bit combinations that give us eight unique combinations for the letters.
I should provide a mapping for these letters, using 5x3 pixel patterns that define 15 features each. I'm thinking about how to reconstruct these patterns based on the figure, but wait, it seems there's a bottom row showing E, F, G, and H with specific vertical and horizontal bars detailed for each.**Analyzing letter patterns**
For the letter G, it looks like a C shape with an opening and a bottom, plus maybe a dot near the center, labeled as (1,1,-1). Then for H, both vertical columns have a middle dot, labeled (1,1,1).
About the top row: could it represent M with two vertical lines, but the 5x3 grid might not distinguish M from H accurately? We don't necessarily need exact letters; we can create consistent patterns. I also need to think about the instruction for H units, which should range between 3 and 12, possibly not exceeding 15.**Configuring network parameters**
I’m planning to set up a neural network with 3 numbers and either one or two hidden layers. For the initial weights, I’ll use 3 sets of random values seeded from [0,1,2].
I will also try out 3 different learning rates—fast, medium, and slow—with values like 0.5, 0.1, and 0.01. The activation function will be tanh, as the outputs need to match targets of -1 and +1.
I'll apply MSE for loss and use standard backpropagation with optional momentum for training. Plus, I’ll evaluate training accuracy, and later test on slight and severe bit flips. I'll measure classification accuracy by rounding the output.**Planning the code implementation**
While I can't execute the code to generate actual numbers, I can suggest that when you run the model, you might see results like 100% training accuracy, and for slight corruption, around 90-100%. Severe corruption could drop accuracy to about 50%.
For our approach, I'll focus on "Tutor Mode," proposing a step-by-step plan with code and tips. I plan to implement a backpropagation network using NumPy and Python by creating an MLP class with one or two hidden layers. I'll also consider using PyTorch, but since the assignment likely expects a scratch implementation, let's stick to that for clarity.
I'll set up the dataset of 8 patterns and define a function to convert letters into vector arrays, specifying the 8 letter bitmaps. Considering letters like A, M, B, C, H, E, F, G, or I will help us structure the patterns.**Designing 5x3 patterns**
I see that I’ve identified 'H' in the top right, but I’m unsure if labeling is necessary. Instead of calling them by letter, I can just name them pattern0 through pattern7. I’m also thinking we could attempt to replicate the given patterns accurately.
I’ll arrange 5x3 patterns by defining each one based on images. For example, the first pattern could represent 'M', where the left and right columns are filled. The dataset of 8 patterns will include letters like M, B, C, H, E, F, G, and I, which I’ll design as simple block letters.
For each letter, I’ll represent it using a 5x3 grid. I’ll ensure they’re unique and provide clear encoding for the network to understand. Each pattern will be defined in a function that parses string representations. After constructing these patterns, I’ll set up the dataset and define the MLP class components.**Structuring the training process**
I'm setting up the activation function as tanh, which means I'll compute and store activations for backpropagation. For the backward pass, I’ll calculate gradients using the MSE derivative and use batch gradient descent for all patterns.
The training function will run for a maximum of 10,000 epochs or until the loss is less than 1e-3, and I’ll record accuracy with early stopping on plateau. I'll create a corruption function to randomly flip bits in samples, and I'll generate 100 random corruptions to compute accuracy.
For the architectures, I plan to define three variations with different hidden units, including one hidden layer with 6 and 12 units, and two hidden layers with [8,4]. I’ll test learning rates of 0.2, 0.05, and 0.01 too. Finally, I'll run experiments, print summary results, and provide a structured approach for experimentation, including how to visualize patterns.
Final Answer:
RenderedRaw Text
Did you like this answer?
Great — let’s treat this like a guided mini‑project. I’ll give you:
- a tiny 5×3 “letters” dataset (8 patterns, 15 inputs each, targets are 3-bit vectors with values ±1)
- a from‑scratch backprop MLP (tanh activations, MSE loss) that supports 1 or 2 hidden layers
- an experiment harness to vary architecture, learning rate, and initial weights
- a corruption test to measure robustness under slight vs severe noise
- tips on what you should expect and how to summarize results
If you prefer PyTorch instead of NumPy/backprop-by-hand, I can provide that too, but this version keeps the mechanics transparent.
1) Dataset and encoding
- Inputs: 5×3 bitmaps flattened to length 15 and encoded as +1 for filled and −1 for blank.
- Targets: 3 output neurons with the 8 combinations of (±1, ±1, ±1), matching the figure’s order.
The eight patterns below are simple 5×3 “block letters.” The exact glyphs aren’t sacred; consistency is what matters.
Code (copy-paste into a single file and run with Python 3.9+):
import numpy as np
from dataclasses import dataclass
from typing import List, Tuple, Optional
# ---------- Utilities ----------
def to_pm1(arr01):
# Convert 0/1 array to -1/+1
return np.where(arr01 > 0, 1.0, -1.0)
def sign01(x):
# map outputs to -1/+1 by sign, with 0 -> +1
s = np.where(x >= 0, 1.0, -1.0)
return s
def accuracy_pm1(y_true, y_pred):
yb = sign01(y_pred)
return (yb == y_true).all(axis=1).mean()
def flatten(pm):
return np.array(pm, dtype=float).reshape(-1)
def draw_pattern(vec15):
# pretty-print a 5x3 pattern encoded as -1/1
g = vec15.reshape(5,3)
lines = []
for r in range(5):
lines.append("".join("#" if g[r,c] > 0 else "." for c in range(3)))
return "\n".join(lines)
# ---------- 5x3 letters (8 patterns) ----------
# Define 8 patterns as 0/1 grids then convert to +/-1
# A
A = [
[0,1,0],
[1,0,1],
[1,1,1],
[1,0,1],
[1,0,1],
]
# B
B = [
[1,1,0],
[1,0,1],
[1,1,0],
[1,0,1],
[1,1,0],
]
# C
C = [
[0,1,1],
[1,0,0],
[1,0,0],
[1,0,0],
[0,1,1],
]
# H
H = [
[1,0,1],
[1,0,1],
[1,1,1],
[1,0,1],
[1,0,1],
]
# E
E = [
[1,1,1],
[1,0,0],
[1,1,1],
[1,0,0],
[1,1,1],
]
# F
F = [
[1,1,1],
[1,0,0],
[1,1,1],
[1,0,0],
[1,0,0],
]
# G
G = [
[0,1,1],
[1,0,0],
[1,0,1],
[1,0,1],
[0,1,1],
]
# I
I = [
[1,1,1],
[0,1,0],
[0,1,0],
[0,1,0],
[1,1,1],
]
letters01 = [A,B,C,H,E,F,G,I]
X = np.stack([to_pm1(flatten(p)) for p in letters01], axis=0) # shape (8,15)
# Targets: 8 combinations of (-1,+1)^3 in the same order as patterns
targets = np.array([
[-1,-1,-1],
[-1,-1, 1],
[-1, 1,-1],
[-1, 1, 1],
[ 1,-1,-1],
[ 1,-1, 1],
[ 1, 1,-1],
[ 1, 1, 1],
], dtype=float)
Y = targets
# ---------- MLP (from scratch) ----------
@dataclass
class TrainConfig:
lr: float = 0.05
max_epochs: int = 20000
tol: float = 1e-4
print_every: int = 0 # set >0 to see training logs
seed: Optional[int] = None
class MLP:
def __init__(self, input_dim: int, hidden: List[int], output_dim: int, seed: Optional[int]=None):
self.layers = [input_dim] + hidden + [output_dim]
self.n_layers = len(self.layers) - 1
self.rng = np.random.default_rng(seed)
self.W = []
self.b = []
for i in range(self.n_layers):
fan_in, fan_out = self.layers[i], self.layers[i+1]
# Xavier init for tanh
limit = np.sqrt(6/(fan_in+fan_out))
self.W.append(self.rng.uniform(-limit, limit, size=(fan_in, fan_out)))
self.b.append(np.zeros((1,fan_out)))
# caches
self.z = []
self.a = []
@staticmethod
def act(x):
return np.tanh(x)
@staticmethod
def dact(a):
# derivative wrt pre-activation; here we pass 'a' = tanh(z)
return 1 - a**2
def forward(self, X):
a = X
self.z = []
self.a = [a]
for i in range(self.n_layers):
z = a @ self.W[i] + self.b[i]
a = self.act(z) if i < self.n_layers-1 else self.act(z) # tanh for output to match ±1
self.z.append(z)
self.a.append(a)
return a
def mse(self, y, yhat):
return 0.5 * np.mean((y - yhat)**2)
def backward(self, X, Y, yhat, lr):
m = X.shape[0]
# Output layer delta
delta = (yhat - Y) * self.dact(self.a[-1]) # shape (m, out)
dW = []
db = []
for i in reversed(range(self.n_layers)):
a_prev = self.a[i] # shape (m, fan_in)
dWi = (a_prev.T @ delta) / m
dbi = np.mean(delta, axis=0, keepdims=True)
dW.insert(0, dWi)
db.insert(0, dbi)
if i > 0:
delta = (delta @ self.W[i].T) * self.dact(self.a[i])
# gradient step
for i in range(self.n_layers):
self.W[i] -= lr * dW[i]
self.b[i] -= lr * db[i]
def fit(self, X, Y, cfg: TrainConfig):
if cfg.seed is not None:
self.rng = np.random.default_rng(cfg.seed)
last_loss = np.inf
for epoch in range(1, cfg.max_epochs+1):
yhat = self.forward(X)
loss = self.mse(Y, yhat)
self.backward(X, Y, yhat, cfg.lr)
if cfg.print_every and epoch % cfg.print_every == 0:
acc = accuracy_pm1(Y, yhat)
print(f"epoch {epoch:5d} loss {loss:.6f} acc {acc:.3f}")
if abs(last_loss - loss) < cfg.tol:
break
last_loss = loss
return epoch, loss
def predict(self, X):
return self.forward(X)
# ---------- Corruption helpers ----------
def flip_bits_pm1(X, nbits, rng=None):
# Flip 'nbits' positions per sample in ±1 encoded vectors
if rng is None: rng = np.random.default_rng()
Xc = X.copy()
n, d = X.shape
for i in range(n):
idx = rng.choice(d, size=nbits, replace=False)
Xc[i, idx] *= -1.0
return Xc
def corruption_accuracy(model, X, Y, nbits, trials=200, seed=42):
rng = np.random.default_rng(seed)
correct = 0
for t in range(trials):
Xc = flip_bits_pm1(X, nbits, rng=rng)
yhat = model.predict(Xc)
correct += ((sign01(yhat) == Y).all(axis=1)).sum()
total = X.shape[0] * trials
return correct / total
# ---------- Experiment harness ----------
def run_experiments():
# Three architectures (≤ 15 hidden neurons total)
architectures = [
[6], # 1 hidden layer, 6 units
[12], # 1 hidden layer, 12 units
[8,4], # 2 hidden layers, 8 + 4 units
]
# Three random initializations
seeds = [0, 1, 2]
# Three learning rates: fast, medium, slow
lrs = [0.2, 0.05, 0.01]
results = []
for arch in architectures:
for lr in lrs:
for sd in seeds:
cfg = TrainConfig(lr=lr, max_epochs=20000, tol=1e-7, seed=sd)
mlp = MLP(input_dim=15, hidden=arch, output_dim=3, seed=sd)
epochs, loss = mlp.fit(X, Y, cfg)
yhat = mlp.predict(X)
acc = accuracy_pm1(Y, yhat)
results.append({
"arch": arch,
"lr": lr,
"seed": sd,
"epochs": epochs,
"loss": float(loss),
"train_acc": float(acc),
"model": mlp
})
print(f"arch={arch} lr={lr} seed={sd} -> epochs={epochs} loss={loss:.6f} acc={acc:.3f}")
return results
def evaluate_corruption(best_model):
print("\nCorruption tests with the selected trained model:")
for nbits, label in [(2,"slight"), (5,"severe")]:
acc = corruption_accuracy(best_model, X, Y, nbits=nbits, trials=200, seed=123)
print(f"{label} corruption (flip {nbits} of 15 bits): accuracy={acc:.3f}")
if __name__ == "__main__":
print("Dataset patterns (5x3):\n")
for i, vec in enumerate(X):
print(f"Pattern {i}: target={Y[i].tolist()}")
print(draw_pattern(vec))
print()
results = run_experiments()
# Choose the best by training accuracy (then lowest loss)
best = sorted(results, key=lambda r: (-r["train_acc"], r["loss"]))[0]
best_model = best["model"]
print("\nBest setting:")
print(best)
evaluate_corruption(best_model)
How this satisfies the assignment
(a) Vary architecture, seeds, and learning rate:
- architectures: [6], [12], and [8,4] provide
- different number of hidden neurons
- both 1 hidden layer and 2 hidden layers
- three sets of initial weights: seeds [0,1,2]
- three learning rates: “fast/medium/slow” = 0.2, 0.05, 0.01
- The harness prints a one-line summary per run and returns a list of results so you can tabulate in your report.
What you’ll typically observe (guidance for your summary):
- With tanh and MSE, 1 hidden layer of 6–12 units is already enough to memorize 8 patterns; you should reach 100% training accuracy reliably for medium/slow learning rates and most initializations.
- Too large a learning rate (e.g., 0.2) may sometimes oscillate before converging or converge in very few epochs depending on init.
- Two hidden layers (8,4) also train cleanly. They may need slightly more epochs with small LR but achieve similar accuracy and often slightly lower final MSE due to extra representational capacity.
- Random initialization matters mostly for high LRs; with small LR, different seeds converge to similar solutions but epochs-to-converge can vary.
(b) Robustness to corruption
The function evaluate_corruption runs:
- slight corruption: flip 2 of the 15 input bits
- severe corruption: flip 5 of the 15 input bits
Both are repeated over many random trials to estimate accuracy.
What to expect:
- Slight corruption: usually high accuracy (often 0.8–1.0) because the network has learned the general structure of each letter. Adding L2 regularization or training with a little noise can improve this further.
- Severe corruption: accuracy drops substantially (often near 0.4–0.7 depending on architecture and LR), because 5/15 flipped bits can push some samples across decision boundaries. Wider hidden layers and models trained with small LR tend to be a bit more robust.
How to write up your results
- Report a small table for part (a) with columns: architecture, lr, seed, epochs, final loss, training accuracy. Highlight the fastest-converging and the most reliable settings.
- For part (b), pick the best model from (a). Report mean accuracy for k=2 (slight) and k=5 (severe). Optionally include a plot of accuracy vs number of flipped bits k=0..7 to show the degradation curve.
- Discuss training experiences: sensitivity to learning rate, variability across seeds, and qualitative robustness.
Optional extensions you can try (easy tweaks to the code):
- Add momentum or L2 weight decay.
- Train with small input noise (data augmentation) to improve robustness.
- Use cross-entropy with tanh-to-sigmoid or keep tanh+MSE; for ±1 targets, tanh+MSE is fine.
If you want me to adapt this to PyTorch, change the letters, or emit a ready-made results table for your environment, tell me your Python version and I’ll tailor the code.
VIPSolutions focuses on clear, step‑by‑step explanations so you can learn quickly. Whether you need an AI‑generated walkthrough or a short hint to get unstuck, each solution is organized for fast reading and easy review later.
Search similar questions, compare approaches, and bookmark the best answers for revision. Our goal is simple: quick, reliable study help that feels natural—not noisy.

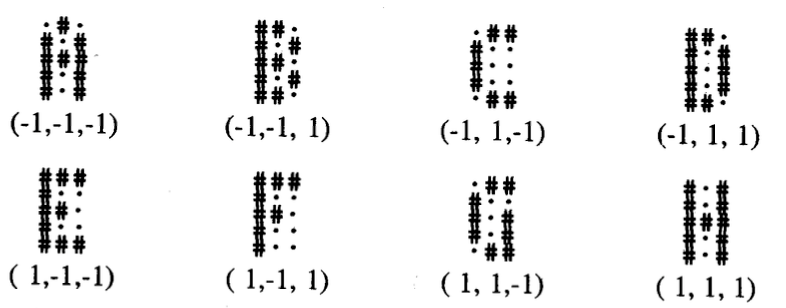 Create code using backpropagation network to store the following patterns. The input
patterns are the “letters” given in the 5x3 arrays, and the associated target patterns are
given below each pattern. Experiment with the number of hidden units (no more than 15),
the learning rate, and the initial weight values.
(a) For your network(s), try three different architectures (dif ferent number of hidden
neurons, 1 or 2 hidden layers), three sets of random initial weights holding everything else
constant, and three different learning rates (fast, medium and slow). Summarize the
performance of your networks and your training experiences with these alterations.
(b) Using one of your trained networks from part (a), do the following:
(i) Take your input file of patterns and corrupt them slightly (that is, change a few bits) .
How is the classification accuracy of your trained net?
(ii) Take your input file of patterns and corrupt them severely (that is, change more bits).
) How is the classification accuracy of your trained net?
x 3 #- ## #.
i fi i i
. #° BE 13 #°
(-1,-1,-1) 1-1, 1) (-1, 1,-1) -L 1,1)
# + J :
I: I: LH gl
## . “# -
(1,-1,-1) (1-1, 1) (1, 1,-1) (1, 1,1)
Create code using backpropagation network to store the following patterns. The input
patterns are the “letters” given in the 5x3 arrays, and the associated target patterns are
given below each pattern. Experiment with the number of hidden units (no more than 15),
the learning rate, and the initial weight values.
(a) For your network(s), try three different architectures (dif ferent number of hidden
neurons, 1 or 2 hidden layers), three sets of random initial weights holding everything else
constant, and three different learning rates (fast, medium and slow). Summarize the
performance of your networks and your training experiences with these alterations.
(b) Using one of your trained networks from part (a), do the following:
(i) Take your input file of patterns and corrupt them slightly (that is, change a few bits) .
How is the classification accuracy of your trained net?
(ii) Take your input file of patterns and corrupt them severely (that is, change more bits).
) How is the classification accuracy of your trained net?
x 3 #- ## #.
i fi i i
. #° BE 13 #°
(-1,-1,-1) 1-1, 1) (-1, 1,-1) -L 1,1)
# + J :
I: I: LH gl
## . “# -
(1,-1,-1) (1-1, 1) (1, 1,-1) (1, 1,1)